您当前正在使用Internet Explorer (IE)浏览器访问本站,本站不兼容性此浏览器
请使用非IE浏览器访问本网站
记录抒写
首页
软件
归档
娱乐
扩展
关于
AI
JockRush
记录文字的魅力
小站告示
admin@wojc.cn
网站公告
关闭
张晨阳
用户的文章
k8s 重启维护节点,这样操作才安全!
2024-05-27
·
技术积累
·
K8s
一个项目用的 k8s 集群发现了个 bug ,处理完成后需要重启节点才能彻底修复。为了避免业务受到影响,在操作节点重启前我们需要将当前节点上运行的所有业务 pod 都驱逐到其他节点上以继续提供服务。这里记录下操作方法及注意事项,特别是结尾总结的注意事项,一定要认真检查。 将 pod 驱逐到其他节点。一般情况下要将某节点上 pod 都驱逐出去我们可以直...
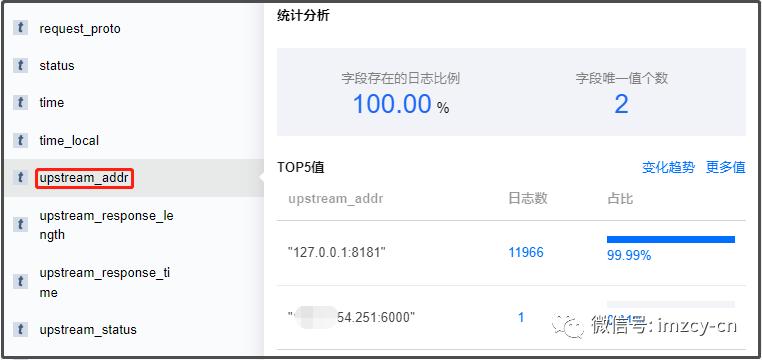
ingress rules 匹配问题导致生产环境大量服务 404 故障记录
2024-05-21
·
技术积累
·
K8s
本文记录一下发生在2023年10月份的一次线上问题的排查过程。一开始是收到生产环境网关下大量请求404的告警,但是没过几分钟自己恢复了。因为报404的都是业务真实在用的接口,于是开始排查原因。最后发现是运维同事新增了一个单独看起来挺正常的 ingress 资源配置,却因为没有考虑当前 k8s 集群下 ingress 资源现状,导致 rules 匹配出...
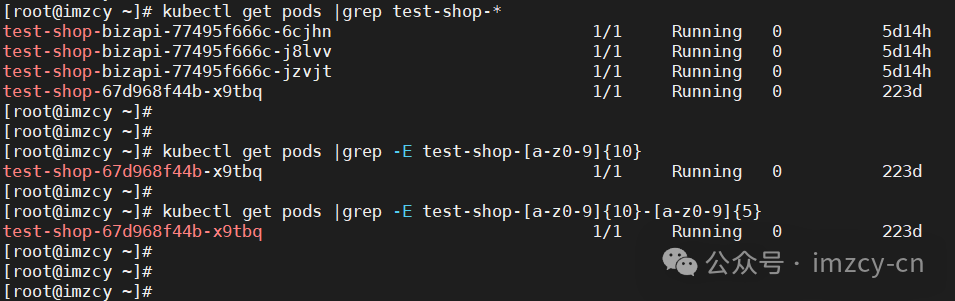
避坑!deployment 生成的 pod 名称竟然有多种格式变化
2024-05-21
·
技术积累
·
K8s
之前写了个脚本:传入 deployment 资源名称作为参数,脚本会正则匹配以该名称开头的 pod 列表(认为匹配到的 pod 是由该 deployment 创建的),再循环去获取 pod 的一些信息。正常使用了几个月后突然发现有些传入的 deployment 资源名称匹配不到 pod 了,于是开始查找原因拿到报异常的 deployment 资源名称...
顶部